Introducing Pithy Papers, a new Language Sciences series where we highlight important and interesting research in the last three months by members from our three research themes, in 150 words or fewer.
Find out why you should discover how signers of young sign languages converge on shared words with shared grammatical properties, how a made-in-Canada language teaching framework would be beneficial and just what a micro-dialect is.

Measuring lexical and structural conventionalization in young sign languages,
Oksana Tkachman, Department of Linguistics
What's new in this paper?
We propose a set of measures for compounds that language users create from scratch, to see how similar they are both in their choice of words and the way these words are put together. These measures are designed to understand how grammatical properties can emerge from language use.
Why is it important?
When a new language emerges, it takes time for language users to converge on a shared lexicon and grammar. Understanding how signers of young sign languages converge on shared words with shared grammatical properties helps us understand how languages could develop in the distant past.
Who should read it?
Any person interested in language, communication, evolution may find this paper interesting. But it will probably be most interesting to people interested in social factors and how these factors influence the way people communicate with each other and how they affect language development.

Associate Professor Monique Bournot-Trites, Department of Language & Literacy Education
What's new in this paper?
We demonstrate that the Canadian language benchmarks (CLB/NCLC), greatly revised in 2012, reflect the Canadian context and are more contextually appropriate and useful for language teachers and policymakers in Canada than the earlier recommended Common European Framework of Reference (CEFR) for use in the K-12 Canadian school context.
Why is it important?
A language framework is a foundation for developing additional language curricula, pedagogy, and assessment, enabling students to become competent in the language they study. The CLB/NCLC are shown to be theoretically based, validated using rigorous criteria set in the Canadian linguistic and cultural context, and address intercultural competence.
Who should read it?
This has an important message for learners, teachers and policy makers who would benefit from an increased use of this made-in-Canada framework offering common national standards for language teaching and assessment. Looking outside Canada for language standards risks losing language diversity and cultural specificity (ironically, when linguistic diversity is celebrated).

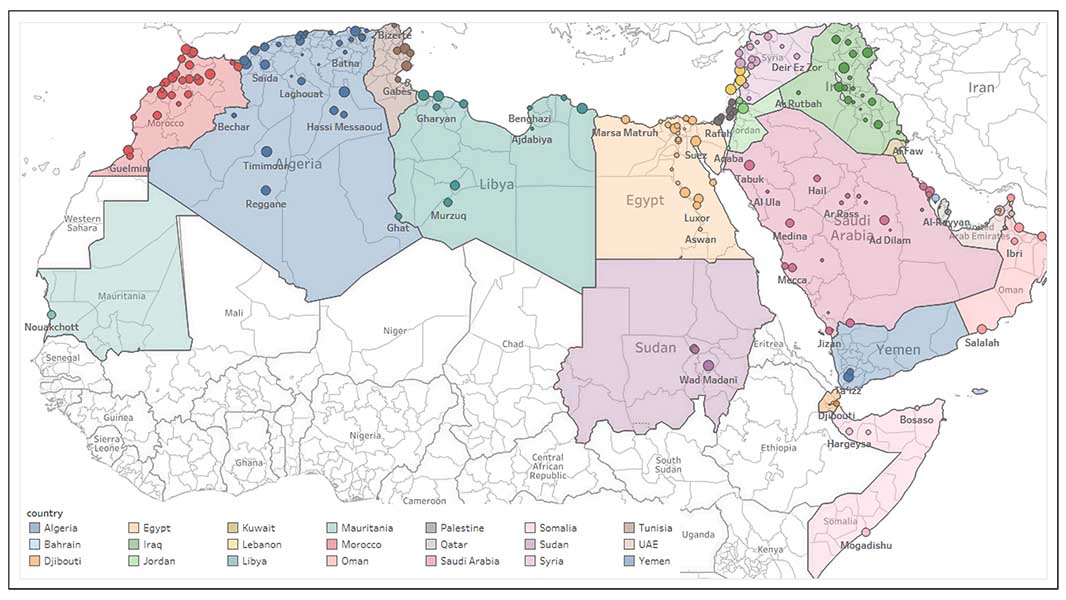
Toward Micro-Dialect Identification in Diaglossic and Code-Switched Environments,
Assistant Professor Muhammad Abdul-Mageed, School of Information and Department of Linguistics
What's new in this paper?
The concept of ‘micro-dialects’ to refer to language variation at geographical levels as small as cities and the computational models to detect them. We used one billion tweet dataset to develop MARBERT, a language model. Using MARBERT, we developed micro-dialect models endowed with knowledge of location and everyday language use.
Why is it important?
We want to create technology that serves everyone. If tools like Siri only understand ‘standard’ English, this excludes large sectors of society. By creating machines that can talk to everyone, we can provide access to services like healthcare to more people. We aim to extend this work to more languages.
Who should read it?
Computer scientists and others interested in natural language technology and its applications. Linguists may find our methods and models interesting as they are focused on micro-variation. Information science and informatics scholars may find relevance in applications of our models and also the theme of improving access to and through technology.
Join the conversation on Twitter (@UBCLangScis) and ask our members about their work!
Main image credit: Muhammad Abdul-Mageed Chiyu Zhang AbdelRahim Elmadany Lyle Ungar